Administrar una base de datos que se encuentra en producción es un reto, como DBAs enfrentamos este escenario día tras día. Sabemos lo importante que es optimizar las consultas que se envían a nuestro servidor para lograr mejorar su tiempo de respuesta. Pero también, es necesario establecer un plan de mantenimiento en ellos para obtener diversos beneficios que van desde mejorar el tiempo de respuesta de las consultas hasta, recuperar nuestro sistema en caso de un desastre.
SQL Server nos brinda un abanico de posibilidades para implementar esto, podemos usar el propio management o implementarlo usando Transact-SQL. Ahora vamos a mostrar una alternativa más, que es a través de Integration Services usaremos como entorno de desarrollo Visual Studio 2015.
Para los que no han escuchado hablar de esta gran y potente herramienta de Microsoft los invito a investigar un poco de los beneficios y todo lo que puede llegar a desarrollar con ella. Ahora, vamos a implementar un plan de mantenimiento en SSIS que abarcará los siguientes puntos:
- Check Database Integrity Task
- Reorganize Index Task
- Rebuild Index Task
- Backup Database Task
NOTA: Los nombres de las tareas puede variar dependiendo del idioma en que usted tenga configurado su IDE.
Para hacerlo más flexible y portátil vamos a hacer que la solución pueda usarse en diferentes servidores sin la necesidad de volver a desplegar el proyecto en nuestro catálogo. Esto lo vamos a lograr gracias a los parámetros y conexiones dinámicas que vamos a asignar al momento de invocar el proyecto ya sea desde el propio catálogo o desde el SQL Server Agent.
Check Database Integrity Task
Esta tarea nos permite realizar lo mismo que en su versión Transact-SQL «DBCC CHECKDB» como ya sabemos, este comando comprueba la asignación e integridad estructural de las tablas y los índices de la base de datos que seleccionemos.
Para empezar con la configuración ubique el componente en el cuadro de herramientas y arrástrelo hacía el control flow. Al hacer doble clic sobre el se abrirá una ventana emergente, es aquí donde empezaremos a configurar la tarea. En su mayoría, encontraremos algunas configuraciones básicas que están presentes siempre pero también algunos componentes comparten configuraciones únicas propias de cada uno.
Uno de los componentes básicos es la cadena de conexión, la mayoría de tareas que usted usará en el control flow necesita de una conexión hacía un servidor o base de datos con la que se trabajará. Una vez que se establece la conexión observamos que se habilitan los siguientes componentes dentro del asistente de configuraciones de la tarea:
- Databases: Aquí es donde seleccionaremos con que base(s) de datos vamos a trabajar.
- Include Indexes: Esta opción se encuentra marcada por defecto lo que quiere decir que la tarea revisará la integridad de los indices para todas las bases de datos que seleccionamos.
Nota: Vamos a trabajar con la opción «All user databases».

Al terminar de seleccionar las bases de datos, observe que se habilitaron cuatro opciones de configuración nuevas, estas son configuraciones opcionales que van a depender mucho de la situación que tenga cada uno. Al igual que con su versión en Transact-SQL usted puede seleccionar que la revisión de integridad se maneje solo a nivel:
- Physical Only: Establece que se limite la comprobación solo a la parte de la estructura física de los distintos componentes de la base de datos, esta opción es recomendable en bases de datos muy grandes donde se ejecuta este comando con frecuencia. Debido a que, puede reducir considerablemente el tiempo de ejecución del comando.
- Tablock: Habilita que bloqueos exclusivos a corto plazo sobre la base de datos con la que se trabaja. Con esta opción ganamos tiempo de ejecución pero perdemos simultaneidad en la base de datos.
Por último, tenemos la opción «Degree of Parallelism» con la cual podemos establecer el grado de paralelismo que se asignan para ejecutar una sola instrucción SQL. Con esto se terminó con la configuración de la tarea y tenemos el primer componente listo.
Reorganize Index Task
Nos permite reorganizar los indices de una o muchas bases de datos, por dentro encapsula la instrucción «ALTER INDEX» de Transact-SQL. También puede utilizarse para compactar tipos de datos muy grandes como image, text, ntext, varchar(max), nvarchar(max), varbinary(max) o xml. Esta tarea puede tardar en ejecutar si es que las bases de datos seleccionadas contienen muchos indices por reorganizar, es por esta razón que debe ejecutarse dentro de una ventana que no afecte el horario de producción.
Ubique el componente en el cuadro de herramientas y arrástrelo al control flow al igual que con el primer componente usted iniciará la configuración dando doble clic sobre el, observe que en la parte de conexión se está reutilizando de forma automática la conexión que creamos antes (si no quisiera usar esta conexión, puede cambiarla desplegando la lista de opciones o creando una nueva conexión).
Seleccione la o las bases de datos con las que va a trabajar y presione «Ok», llegados a este punto quiero resaltar que si usted selecciona solo una base de datos, el cuadro de selección de «Object» se habilita. Esto es por qué, al trabajar con solo una BD usted tiene la posibilidad de escoger los objetos que contiene la misma, puede seleccionar reorganizar solo vistas, tablas o la combinación de ambas de nuevo esto depende de la necesidad de cada uno. Al configurar esto podemos ganar tiempo de ejecución pero tal vez perdemos flexibilidad al tener que crear varios componentes para distintas bases de datos.
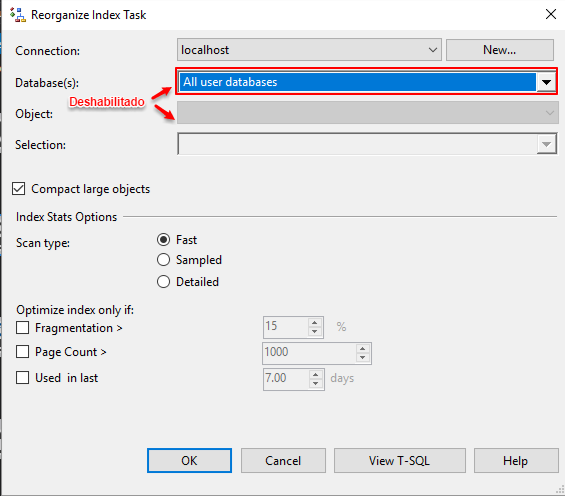
Observemos que en la sección de «Index Stats Options» podemos seleccionar el tipo de escaneo para los objetos y distintas filtros para que se considere o no reorganizar un índice. Una vez que usted ha establecido las conexiones y establecido sus filtros puede guardar los cambios, con esto se terminó con la segunda tarea del plan de mantenimiento.
Rebuild Index Task
Este componente nos permite reconstruir los indices de una o varias bases de datos, al igual que el componente anterior esta tarea puede tomar un tiempo prolongado en ejecutarse es por esto que se recomienda ejecutarlo en una ventana programada. Empezamos seleccionando la conexión y las bases de datos con la que va a trabajar, en esta tarea también se habilita o deshabilita el cuadro de selección de «Object» dependiendo de la cantidad de bases de datos que seleccionemos.
Lo nuevo aquí es la sección de «Free space option» y «Advance options»:
- Free space option: En este apartado usted puede escoger que el factor de relleno de los indices sea el mismo que se uso al crearlos o puede establecer uno nuevo.
- Advance option: Aquí tiene opciones avanzadas que van desde almacenar en TempDB los datos del índice para que sean ordenamos al momento de reconstruirlo o establecer el grado de paralelismo.
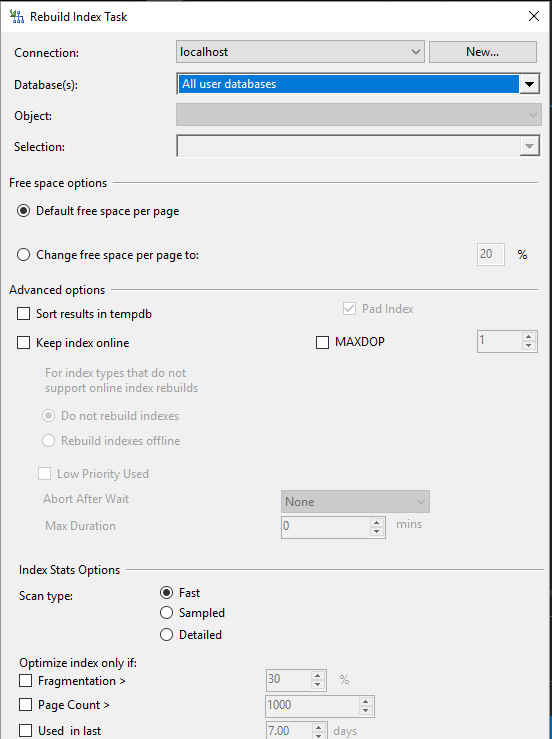
Terminada la configuración se tiene tres de cuatro tareas terminadas.
Backup Database Task
Podemos realizar el respaldo de una o muchas bases de datos dentro de un mismo servidor, si decidimos realizar la copia de seguridad para una sola base de datos podremos elegir el componente de copia de seguridad de la base de datos. Ubique el componente en el cuadro de herramientas y arrástrelo al control flow, al iniciar la configuración se puede observar la siguiente ventana:
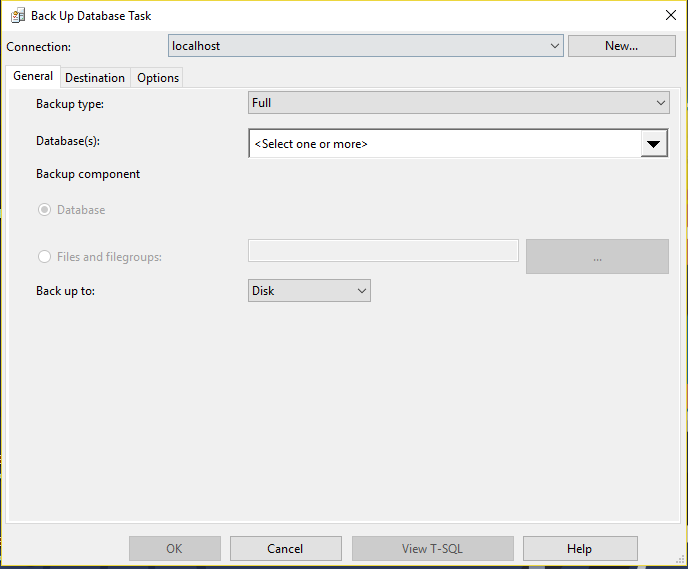
Tenemos las siguientes pestañas dentro de esta tarea:
- General: Aquí vamos a escoger el tipo de backup, las bases de datos con las que vamos a trabajar y en donde se realizará la copia de seguridad (Disk, Tape o URL).
- Destination: En esta pestaña tenemos dos opciones, podemos realizar copia de seguridad en uno o varios archivos o podemos crear un archivo de copia de seguridad para cada base de datos. Además, aquí seleccionara el destino donde se alojaran los backups.
- Optional: Aquí podemos escoger distintas opciones que van desde encriptar el archivo de backup hasta establecer la comprensión de la copia de seguridad.
Luego de que usted terminó de configurar la tarea puede guardar los cambios que realizó, con esto usted tiene todas la tareas del plan de mantenimiento terminadas y listas.
Para ejecutar las tareas en secuencia podemos seleccionar el primer componente, observemos que aparece una flecha debajo de este arrastre la flecha hasta que conecte con el componente más cercano:

Ahora realice lo mismo con todos los componentes de su paquete, debería tener el siguiente resultado:
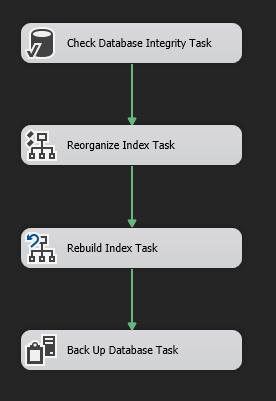
Nota: Usted puede renombrar los componentes de tal manera que puedan explicar mejor cual es la función de cada uno sin necesidad de examinarlos a detalle.
Deployment Mode
Para poder desplegar su proyecto usted debe establecer un modo de despliegue, Integration Services cuenta con dos opciones para este escenario:
- Puede establecer el proyecto en «Convert to Project Deployment Mode».
- Puede establecer el paquete en «Convert to Package Deployment Mode» (implementado en la versión SQL Server 2016 Integration Services)
Puede obtener mas información en el siguiente enlace: https://docs.microsoft.com/es-es/sql/integration-services/packages/deploy-integration-services-ssis-projects-and-packages?view=sql-server-2017
Vamos a convertir el proyecto en modo «Convert to Project Deployment Mode», para eso ubicamos en la barra superior Project-> Convert Deployment Model.
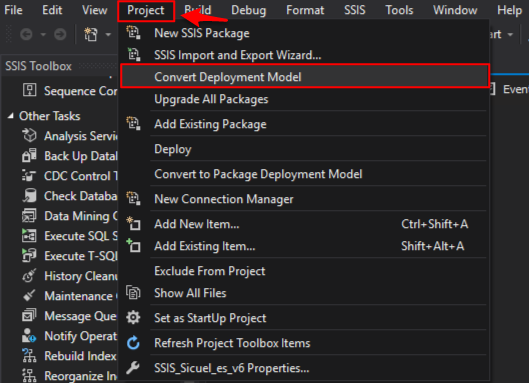
Luego de finalizar con el asistente, obtendrá el siguiente mensaje para que guarde los cambios en el proyecto:

Luego de que usted configuró este modo de despliegue tiene habilitada la opción para hacer «Deploy» sobre la solución:

Aún no vamos a desplegar la solución, hasta este punto usted tiene el plan de mantenimiento casi terminado. Ahora vamos a asignar el valor de la cadena de conexión al momento de invocar al paquete.
Dynamic Params
En la parte superior del control flow seleccione la pestaña de «Parameters».
NOTA: Cuando usted despliega el paquete en modo «Convert to package model» no puede establecer parámetros.

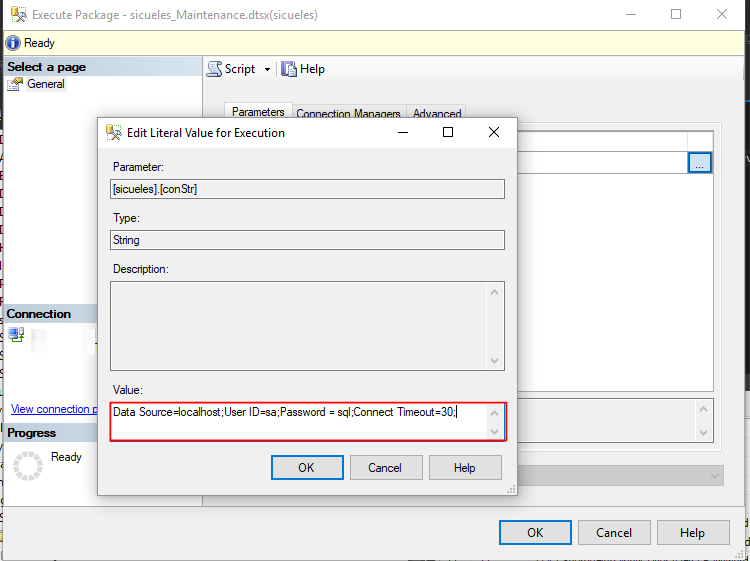
Vamos a crear un parámetro de tipo «String» vamos a colocar «localhost» ya qué, más adelante vamos a usar este parámetro para remplazar el «ConnectionString» de nuestra conexión. Entonces, al momento de evaluar el parámetro si no contiene un valor la conexión se puede deshabilitar.

Ahora vamos sobre la cadena de conexión que creamos antes y damos clic derecho -> Propiedades. Esto nos mostrará el panel de propiedades para el componente, en SSIS la mayoría de las tareas tienen este panel en donde puedes hacer cosas muy interesantes.
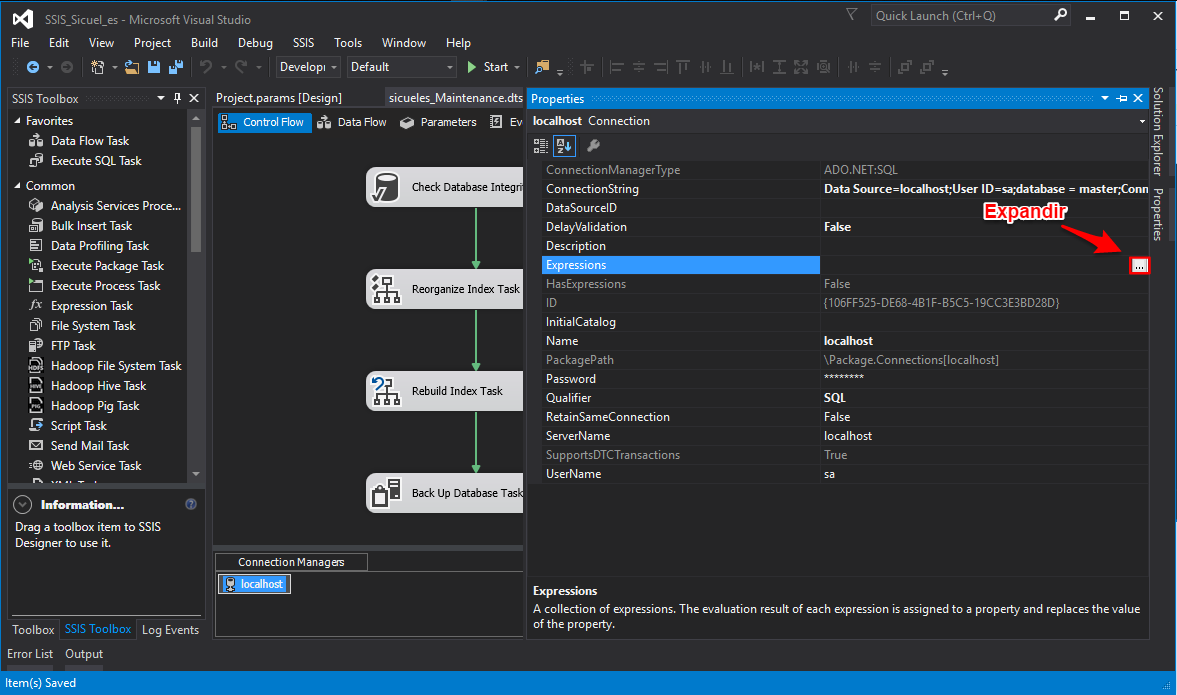
Ubique la sección de expresiones y expanda el panel con los tres puntos que aparecen al costado. Luego, en la ventana emergente ubíquese sobre la columna de «Property» y seleccione «ConnectionString»:
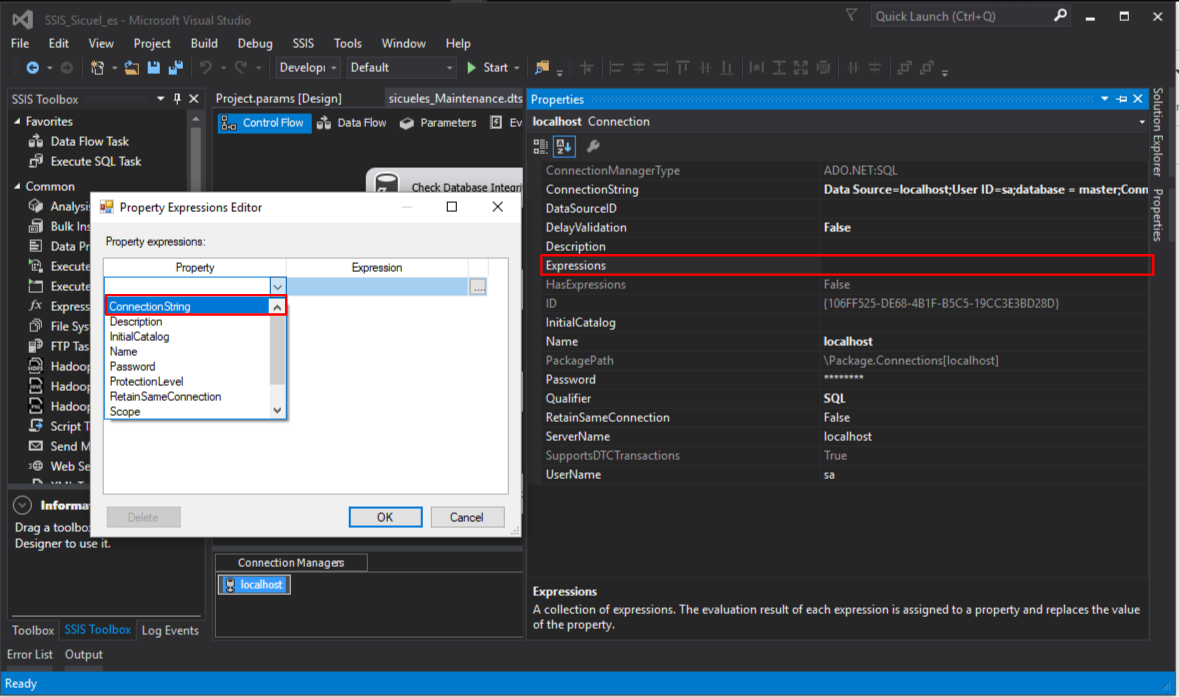
Expanda la columna de expresiones y busqué el parámetro que creó antes, una vez que lo ubique asígnelo al valor de la propiedad «ConectionString»:
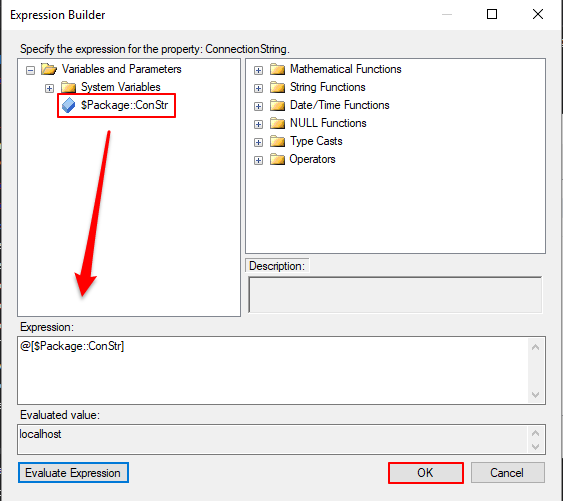
Ahora fíjese que la conexión que teníamos antes cambió para mostrar que esta usando una expresión:
Para finalizar, vamos a desplegar el proyecto a nuestro catálogo de SSIS:
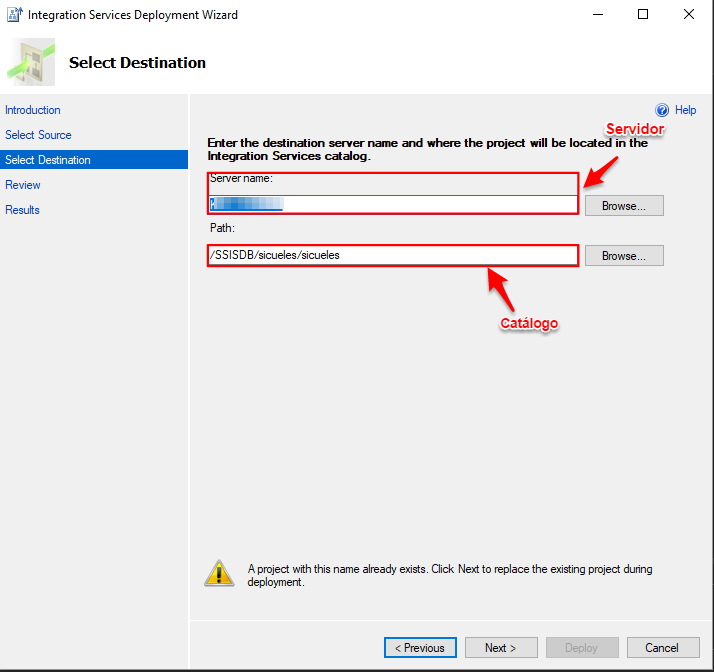
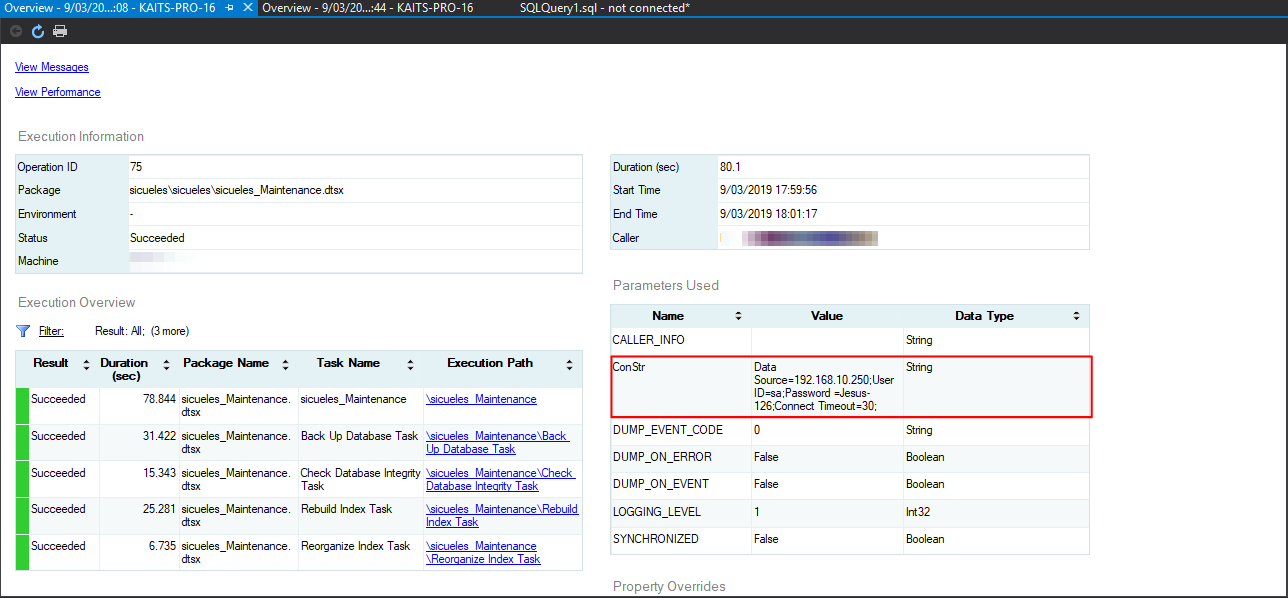
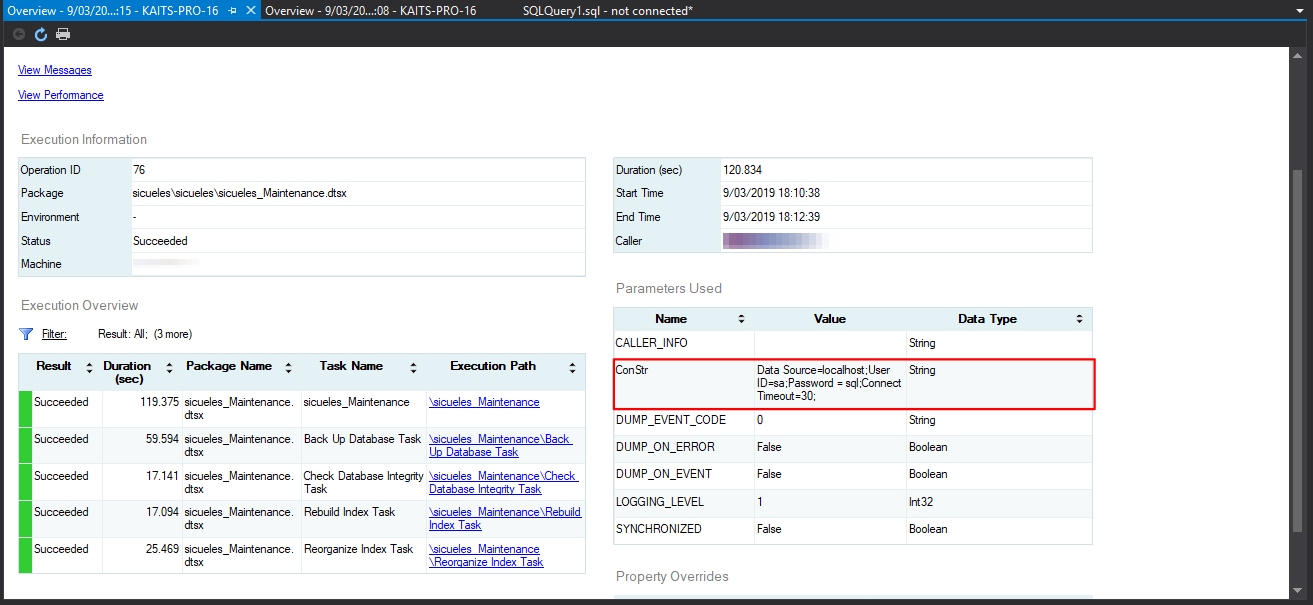
Para probar que la cadena de conexión funcione de forma correcta he creado una máquina virtual en donde monté un servidor de SQL Server 2016 con unas cuantas bases de datos, entonces tenemos dos instancias en donde vamos a ejecutar el proceso:
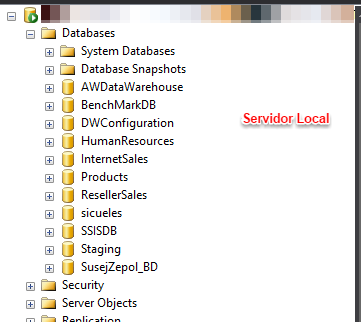
NOTA: Para la tarea de backup el paquete que acabamos de crear necesita que exista la carpeta destino en ambos servidores:

Para poder probar la solución ubíquese sobre el catálogo de Integration Services y busqué el proyecto que acaba de desplegar:
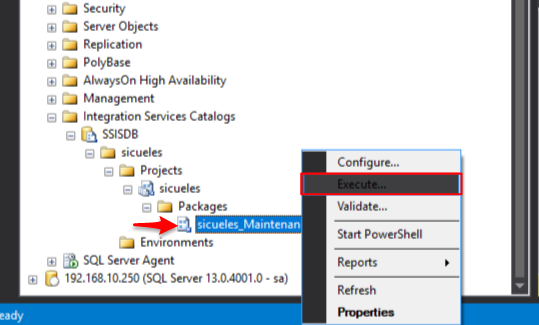
Al ejecutar el paquete note que se muestra una pestaña en donde usted puede ingresar el valor del parámetro que creó dentro de la solución:
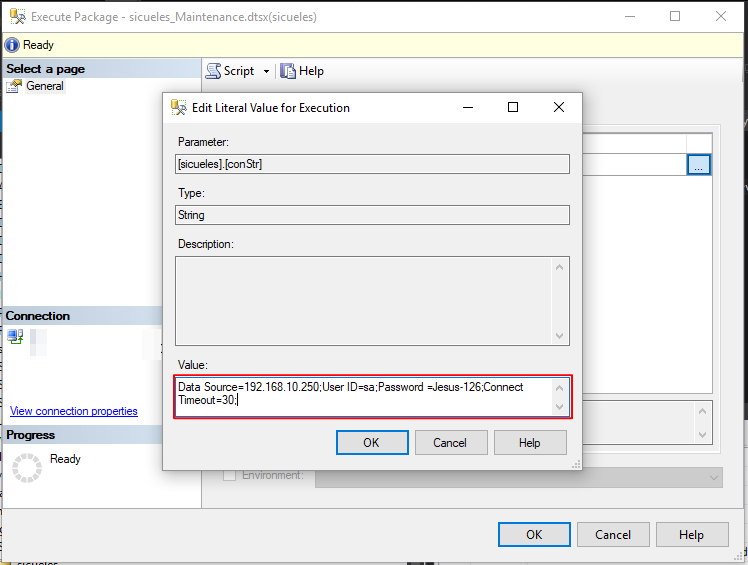
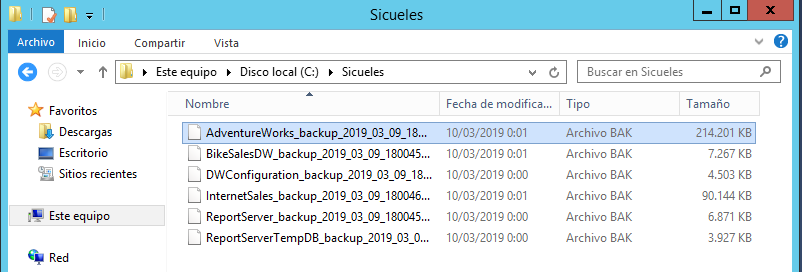
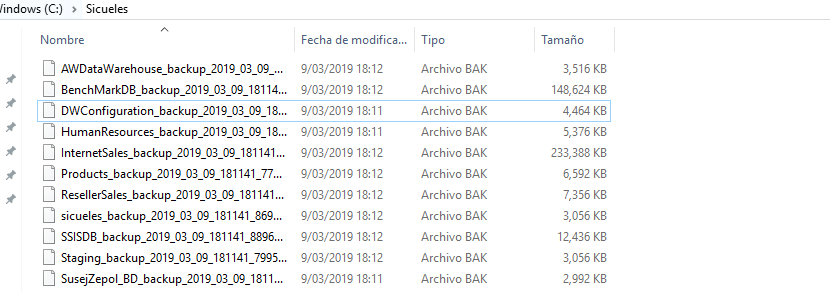
Podemos ver que los procesos terminaron con éxito y los backups de nuestras bases de datos se encuentran en la ruta que configuramos en cada servidor:
SERVIDOR VIRTUAL:
SERVIDOR LOCAL:
Ahora podemos configurar este paquete en un job de SQL Server Agent:
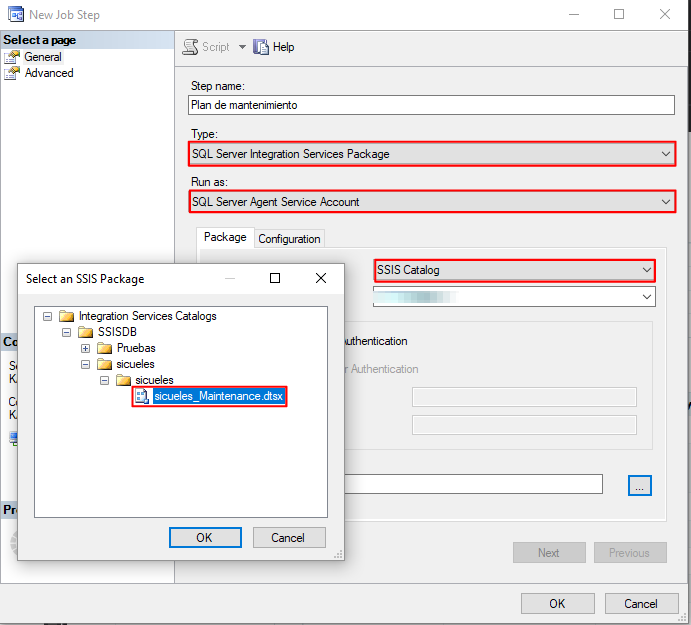
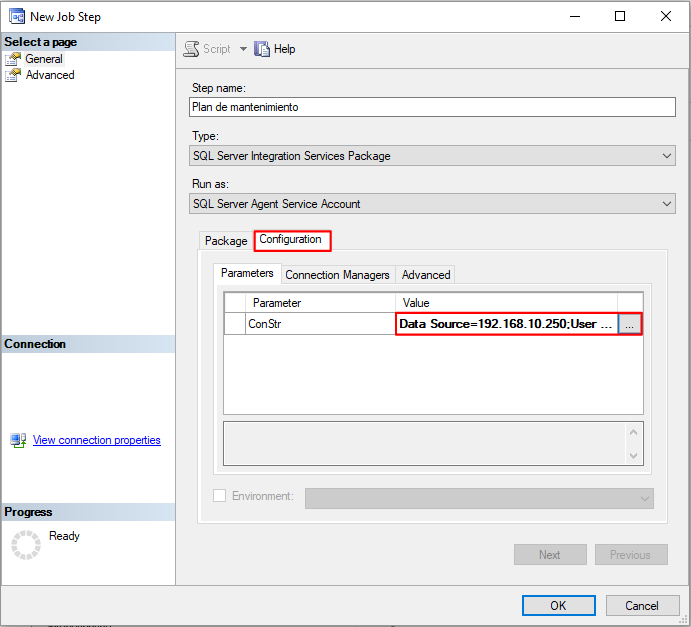
De esta forma podemos asegurarnos de tener el respaldo de nuestras bases y nuestros indices al día.
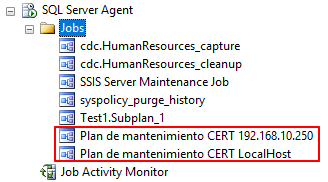
Espero les sirva mucho en su ambiente laboral y profesional!!!
Autor: Jesus Lopez Mesia
Linkedin: https://www.linkedin.com/in/jesus-miguel-lopez-mesia-880a01124/
Muy buena alternativa!!
Hola, Muchas gracias por el artículo. un apunte, ¿No se tendría que hace primero el rebuild >30% y después el Reorganice >15%?, sino nunca te hará rebuild, ¿no? porque todo lo superior al 15% te lo reorganizará y saldrá de ahí ya sin fragmentación por lo que no entrará nunca a Rebuild.¿ Lo estoy planteando mal? Muchas gracias y un saludo.
Tienes toda la razón Nait, es correcto tu planteamiento.